Compounds
Compound
- class hippo.compound.Compound(animal: HIPPO, db: Database, id: int, inchikey: str, alias: str, smiles: str, mol: Mol | bytes | None = None, metadata: dict | None = None)[source]
A
Compoundrepresents a ligand/small molecule with stereochemistry removed and no atomic coordinates. I.e. it represents the chemical structure. It’s name is always an InChiKey. If a compound is an elaboration it can have aCompound.bases()property which is anotherCompound.Compoundobjects are target-agnostic and can be linked to any number of catalogue entries (Quote) or synthetic pathways (Reaction).Attention
Compoundobjects should not be created directly. Instead useHIPPO.register_compound()orHIPPO.compounds(). See Getting started with HIPPO and Adding data into HIPPO.- add_base(base: Compound | int, commit: bool = True) None[source]
Add a base
Compoundthis molecule is derived from.
- add_stock(amount: float, *, purity: float | None = None, entry: str | None = None, location: str | None = None, return_quote: bool = True) int | Quote[source]
Register a certain quantity of compound stock in the Database.
- Parameters:
amount – Amount in
mgpurity – Purity fraction
0 < purity <= 1, defaults toNonelocation – String describing where this stock is located, defaults to
Nonereturn_quote – If
TrueaQuoteobject is returned instead of its ID, defaults toTrue
- Returns:
The inserted
Quoteobject or ID (seereturn_quote)
- property alias: str
Returns the compound’s alias
- as_ingredient(amount: float, max_lead_time: float = None, supplier: str = None, get_quote: bool = True, quote_none: str = 'quiet') Ingredient[source]
Convert this compound into an
Ingredientobject with an associated amount (inmg) andQuoteif available.- Parameters:
amount – Amount in
mgsupplier – Only search for quotes with the given supplier, defaults to
Nonemax_lead_time – Only search for quotes with lead times less than this (in days), defaults to
None
- property atomtype_dict: dict[str, int]
Get a dictionary with atomtypes as keys and corresponding quantities/counts as values.
- property bases: CompoundSet | None
Returns the base compound for this elaboration
- classify(draw: bool = True) list[tuple[str, int]][source]
Find RDKit Fragments within the compound molecule and draw them
- Parameters:
draw – Draw the annotated molecule, defaults to
True- Returns:
A list of tuples containing a descriptor (
str) and count (int) pair
- property dict: dict
Returns a dictionary of this compound. See
Compound.get_dict()
- draw(align_substructure: bool = False) None[source]
Display this compound (and its base if it has one)
Attention
This method is only intended for use within a Jupyter Notebook.
- Parameters:
align_substructure – Align the two drawing by their common substructure, defaults to
False
- property elabs
Returns the base compound for this elaboration
- property formula: str
Get the chemical formula
- get_base_ids() list[int][source]
Get a list of
CompoundID’s that this object is a superstructure of
- get_dict(*, mol: bool = True, alias: bool = True, inchikey: bool = True, metadata: bool = True, poses: bool = True, count_by_target: bool = False, num_reactant: bool = True, num_reactions: bool = True, bases: bool = True, elabs: bool = True, tags: bool = True) dict[source]
Returns a dictionary representing this
Compound- Parameters:
mol – Include a
rdkit.Chem.Mol object, defaults toTruemetadata – Include metadata, defaults to
Trueposes – Include dictionaries of associated
Poseobjects, defaults toTruecount_by_target – Include counts by protein
Target, defaults toFalse. Only applicable whencount_by_target = True.num_reactant – include num_reactant column
num_reactions – include num_reactions column
bases – include bases column
elabs – include elabs column
tags – include tags column
- Returns:
A dictionary
- get_inspirations(debug: bool = True, none: str = 'warning') PoseSet[source]
Since inspirations map
Poseobjects to each other rather thanCompoundobjects, this only works if there are poses registerd for this compound or it’s elaborations/superstructures.- Returns:
a
PoseSetobject
- get_quotes(min_amount: float | None = None, supplier: str | None = None, max_lead_time: float | None = None, none: str = 'quiet', pick_cheapest: bool = False, df: bool = False) list[Quote][source]
Get all quotes associated to this compound
- Parameters:
min_amount – Only return quotes with amounts greater than this, defaults to
Nonesupplier – Only return quotes with the given supplier, defaults to
Nonemax_lead_time – Only return quotes with lead times less than this (in days), defaults to
Nonenone – Define the behaviour when no quotes are found. Choose error to raise print an error.
pick_cheapest – If
Trueonly the cheapestQuoteis returned, defaults toFalsedf – Returns a
DataFrameof the quoting data, defaults toFalse
- Returns:
List of
Quoteobjects,DataFrame, or singleQuote. Seepick_cheapestanddfparameters
- get_reactions(as_reactant: bool = False, permitted_reactions: ReactionSet = None, none: str = 'error') ReactionSet[source]
Get the associated
Reactionobjects. By default this function returns all reaction resulting in thisCompoundas a product, unlessas_reactantis set toTrue.- Parameters:
as_reactant – Search for
Reactionobjects using thisCompoundas a reactant instead of a product, defaults toFalsepermitted_reactions – Provide a
ReactionSetby which to filter the resultsnone – Define the behaviour when no quotes are found. Choose error to raise print an error, defaults to
'error'
- get_recipes(*, amount: float = 1, debug: bool = False, pick_cheapest: bool = False, quoted_only: bool = False, supplier: None | str = None, **kwargs)[source]
Get
Recipeobjects that result in this compound. SeeRecipe.from_compounds()
- get_superstructure_ids() list[int][source]
Get a list of
CompoundID’s that this object is a substructure of
- property id: int
Returns the compound’s database ID
- property inchikey: str
Returns the compound’s InChiKey
- property is_base: bool
Is this Compound the basis for any elaborations?
- property is_elab: bool
Is this Compound the based on any other compound?
- property is_product: bool
Is this Compound a product of at least one reaction
- property mol: Mol
Returns the compound’s RDKit Molecule
- property molecular_weight: float
Get the molecular weight
- property name: str
Returns the compound’s InChiKey
- property num_atoms_added: int | list[int] | None
Calculate the number of atoms added relative to the base compound
- property num_bases: int
Get the number of base compounds for this elaboration
- property num_heavy_atoms: int
Get the number of heavy atoms
- property num_poses: int
Returns the number of associated poses
- property num_reactant: int
Returns the number of associated reactions (reactant)
- property num_reactions: int
Returns the number of associated reactions (product)
- property num_rings: int
Get the number of rings
- place(*, reference: ~hippo.pose.Pose, inspirations: list[~hippo.pose.Pose] | None = None, max_ddG: float = 0.0, max_RMSD: float = 2.0, output_dir: str = 'wictor_place', tags: list[str] = None, metadata: <property object at 0x74862add0770> = None, overwrite: bool = False) Pose[source]
Generate a new pose for this compound using Fragmenstein.
- Parameters:
reference – Choose the
Poseto use as the reference protein conformationinspirations – Choose the (virtual) hits to to define the ligand reference, defaults to the
reference’s inspirationsmax_ddG – Maximum
ddGvalue permitted for a valid ligand conformation, defaults to0.0max_RMSD – Maximum
RMSDvalue permitted for a valid ligand conformation, defaults to2.0output_dir – Output directory for Fragmenstein files, defaults to
wictor_placetags – Tags to assign to the created pose, defaults to
[]metadata – A dictionary of metadata to assign to this compound, defaults to
{}overwrite – Delete old poses, defaults to
False
- property reaction: Reaction
Returns the reaction resulting in this compound (will return first if multiple, with a warning)
- property reactions: ReactionSet
Returns the reactions resulting in this compound
- set_alias(alias: str, commit=True) None[source]
Set this
Compound’s alias.- Parameters:
alias – The alias
commit – Commit the changes to the
Database, defaults toTrue
- property smiles: str
Returns the compound’s (flattened) smiles
Ingredient
- class hippo.compound.Ingredient(db, compound, amount, quote, max_lead_time=None, supplier=None)[source]
An ingredient is a
Compoundwith a fixed quanitity and an attached quote.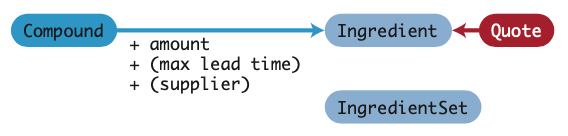
Attention
Ingredientobjects should not be created directly. Instead useCompound.as_ingredient().- property amount: float
Returns the amount (in
mg)
- property compound_price_amount_str: str
String representation including
Compound,Price, and amount.
- get_cheapest_quote_id(min_amount: float | None = None, supplier: str | None = None, max_lead_time: float | None = None, none: str = 'quiet') int | None[source]
Query quotes associated to this ingredient, and return the cheapest
- Parameters:
min_amount – Only return quotes with amounts greater than this, defaults to
Nonesupplier – Only return quotes with the given supplier, defaults to
Nonemax_lead_time – Only return quotes with lead times less than this (in days), defaults to
Nonenone – Define the behaviour when no quotes are found. Choose error to raise print an error.
- get_quotes(**kwargs) list[Quote][source]
Wrapper for
Compound.get_quotes()
- property max_lead_time: float
Returns the max_lead_time (in days) from the original quote query
- property supplier: str
Returns the supplier from the original quote query
CompoundTable: All Compounds
- class hippo.cset.CompoundTable(db: Database)[source]
Class representing all
Compoundobjects in the ‘compound’ table of theDatabase.Attention
CompoundTableobjects should not be created directly. Instead use theHIPPO.compounds()property. See Getting started with HIPPO and Adding data into HIPPO.Use as an iterable
Iterate through
Compoundobjects in the table:for compound in animal.compounds: ...
Selecting compounds in the table
The
CompoundTablecan be indexed withCompoundIDs, names, aliases, or list/sets/tuples/slices thereof:ctable = animal.compounds # indexing individual compounds comp = ctable[13] # using the ID comp = ctable["BSYNRYMUTXBXSQ-UHFFFAOYSA-N"] # using the InChIKey comp = ctable["aspirin"] # using the alias # getting a subset of compounds cset = ctable[13,15,18] # using IDs (tuple) cset = ctable[[13,15,18]] # using IDs (list) cset = ctable[set(13,15,18)] # using IDs (set) cset = ctable[13:18] # using a slice
Tags and base compounds can also be used to filter:
cset = animal.compounds(tag='hits') # select compounds tagged with 'hits' cset = animal.compounds(base=comp) # select elaborations of comp
- self(*, tag: str = None, base: int | Compound = None, smiles: str | None = None, **kwargs) CompoundSet | Compound | None[source]
Filter compounds by a given tag, base, or it’s SMILES string. See
CompoundTable.get_by_tag()andCompoundTable.get_by_base()- Parameters:
tag – optional tag to filter by
base – optional
CompoundID or object to filter bybase – optional SMILES string to filter by
- Returns:
CompoundSetif searching by tag or base, elseCompoundobject
- self[key: int | str | tuple | list | set | slice] Compound[source]
Get a member
Poseobject or subsetPoseSetthereof.- Parameters:
key – Can be an integer ID, negative integer index, alias or inchikey string, list/set/tuple of IDs, or slice of IDs
- property bases: CompoundSet
Returns a
CompoundSetof all compounds that are the basis for a set of elaborations
- draw() None[source]
2D grid of drawings of molecules in this set
Attention
This method instantiates a
CompoundSetcontaining all compounds, it is recommended to instead select a subset for display. This method is only intended for use within a Jupyter Notebook.
- property elabs: CompoundSet
Returns a
CompoundSetof all compounds that are a an elaboration of an existing base
- get_by_base(base: Compound | int) CompoundSet[source]
Get all compounds that elaborate the given base compound
- Parameters:
base –
Compoundobject or ID to search by
- get_by_metadata(key: str, value: str | None = None)[source]
Get all child compounds by their metadata. If no value is passed, then simply containing the key in the metadata dictionary is sufficient
- Parameters:
key – metadata key
value – metadata value (Default value = None)
- get_by_metadata_substring_match(substring: str) CompoundSet[source]
Get
CompoundSetof poses with metadata JSON containing substring
- get_by_tag(tag: str, inverse: bool = False) CompoundSet[source]
Get all child compounds with a certain tag
- Parameters:
tag – tag to filter by
- property ids: list[int]
Returns the IDs of child compounds
- property inchikeys: list[str]
Returns the inchikeys of all compounds
- interactive() None[source]
Interactive widget to navigate compounds in the table
Attention
This method instantiates a
CompoundSetcontaining all compounds, it is recommended to instead select a subset for display. This method is only intended for use within a Jupyter Notebook.
- property intermediates: CompoundSet
Returns a
CompoundSetof all compounds that are products and reactants
- property names: list[str]
Returns the names of child compounds
- property num_bases: int
Returns the number of compounds that are the basis for a set of elaborations
- property num_elabs: int
Returns the number of compounds that are a an elaboration of an existing base
- property num_intermediates: int
Returns the number of intermediates (see
CompoundTable.intermediates())
- property num_products: int
Returns the number of products (see
CompoundTable.products())
- property num_reactants: int
Returns the number of reactants (see
CompoundTable.reactants())
- property products: CompoundSet
Returns a
CompoundSetof all compounds that are a product of a reaction but not a reactant
- property reactants: CompoundSet
Returns a
CompoundSetof all compounds that are used as a reactants
- property tags: set[str]
Returns the set of unique tags present in this compound set
CompoundSet: Set of Compounds
- class hippo.cset.CompoundSet(db: Database, indices: list = None, sort: bool = True, name: str | None = None)[source]
Object representing a subset of the ‘compound’ table in the
Database.Attention
CompoundSetobjects should not be created directly. Instead use theHIPPO.compounds()property. See Getting started with HIPPO and Adding data into HIPPO.Use as an iterable
Iterate through
Compoundobjects in the set:cset = animal.compounds[:100] for compound in cset: ...
Check membership
To determine if a
Compoundis present in the set:is_member = compound in cset
Selecting compounds in the set
The
CompoundSetcan be indexed like standard Python lists by their indicescset = animal.compounds[1:100] # indexing individual compounds comp = cset[0] # get the first compound comp = cset[1] # get the second compound comp = cset[-1] # get the last compound # getting a subset of compounds using a slice cset2 = cset[13:18] # using a slice
Tags and base compounds can also be used to filter:
cset = animal.compounds(tag='hits') # select compounds tagged with 'hits' cset = animal.compounds(base=comp) # select elaborations of comp
- self + other: Compound | CompoundSet | IngredientSet | int CompoundSet[source]
Add a
Compoundobject or ID to this set, or add multiple at once whenotheris aCompoundSetorIngredientSet
- other: Compound | Ingredient | int in self[source]
Check if compound or ingredient is a member of this set
- self[key: int | slice] Compound | CompoundSet[source]
Get compounds or subsets thereof from this set
- Parameters:
key – integer index or slice of indices
- self - other: CompoundSet | IngredientSet CompoundSet[source]
Subtract a
Compoundobject or ID to this set, or subtract multiple at once whenotheris aCompoundSetorIngredientSet
- self ^ other: CompoundSet[source]
Exclusive OR set operation, returns all compounds in either set but not both
- add(compound: Compound | int) None[source]
Add a compound to this set
- Parameters:
compound – compound to be added
- as_ingredientset(amount: float | list[float] = 1, supplier: str | list | None = None) IngredientSet[source]
Get an
IngredientSetfor these compounds
- property atomtype_dict: dict[str, int]
Get a dictionary with atomtypes as keys and corresponding quantities/counts as values
- property avg_num_atoms_added: float
Calculate the average number of atoms added w.r.t the base
- Returns:
average number of atoms added values for compounds which have a base
- property bases: CompoundSet
Get the base compounds that have at least one elaboration in this set
- Returns:
- copy() CompoundSet[source]
Returns a copy of this set
- count_by_tag(tag: str) CompoundSet[source]
Count all child compounds with a certain tag
- Parameters:
tag – tag to filter by
- draw() None[source]
Draw a grid of all contained molecules.
Attention
This method is only intended for use within a Jupyter Notebook.
- property elab_df: pd.DataFrame
Get a DataFrame summarising the elaborations in this CompoundSet
- property elaboration_balance: float
Measure of how evenly elaborations are distributed across bases in this set
- property elabs: CompoundSet
Returns a
CompoundSetof all compounds that are a an elaboration of an existing base
- property formula: str
Get the combined chemical formula for all compounds
- get_all_possible_reactants(debug: bool = False) CompoundSet[source]
Recursively searches for all the reactants that could possible be needed to synthesise these compounds.
- Parameters:
debug – Increased verbosity for debugging (Default value = False)
- get_all_possible_reactions(debug: bool = False) ReactionSet[source]
Recursively searches for all the reactants that could possible be needed to synthesise these compounds.
- Parameters:
debug – Increased verbosity for debugging (Default value = False)
- get_by_base(base: Compound | int, none: str = 'error') CompoundSet[source]
Get all compounds that elaborate the given base compound
- Parameters:
base –
Compoundobject or ID to search by
- get_by_metadata(key: str, value: str | None = None) CompoundSet[source]
Get all child compounds with by their metadata. If no value is passed, then simply containing the key in the metadata dictionary is sufficient
- Parameters:
key – metadata key
value – metadata value (Default value = None)
- get_by_metadata_substring_match(substring: str) CompoundSet[source]
Get
CompoundSetof poses with metadata JSON containing substring
- get_by_tag(tag: str, inverse: bool = False) CompoundSet[source]
Get all child compounds with a certain tag
- get_df(smiles: bool = True, inchikey: bool = False, alias: bool = True, mol: bool = False, metadata: bool = False, expand_metadata: bool = True, poses: bool = False, num_reactant: bool = False, num_reactions: bool = False, num_poses: bool = False, tags: bool = False, bases: bool = False, elabs: bool = False, routes: bool = False, debug: bool = False, **kwargs) DataFrame[source]
Get a DataFrame representation of this set
- Parameters:
smiles – include SMILES column (Default value = True)
inchikey – include InChIKey column (Default value = False)
alias – include alias column (Default value = True)
mol – include
rdkit.Chem.Molin output (Default value = False)metadata – include metadata in output (Default value = False)
expand_metadata – create separate column for each metadata key (Default value = True)
poses – include poses in output (Default value = False)
num_reactant – include num_poses column
num_reactant – include num_reactant column (number of reactions where compound is a reactant)
num_reactions – include num_reactions column (number of reactions where compound is a product)
tags – include tags column
bases – include bases column
elabs – include elabs column
# :param count_by_target: count poses by target (Default value = False)
- get_dict() dict[source]
Get a dictionary object with all serialisable data needed to reconstruct this set
- get_quoted(*, supplier: str = 'any') CompoundSet[source]
Get all member compounds that have a quote from given supplier
- Parameters:
supplier – supplier name (Default value = ‘any’)
- get_recipes(amount: float = 1, debug: bool = False, pick_cheapest: bool = False, permitted_reactions: ReactionSet | None = None, quoted_only: bool = False, supplier: None | str = None, **kwargs)[source]
Generate the
Recipeto make these compounds.
- get_risk_diversity(debug: bool = False) float[source]
Calculate the average spread of risk (#atoms added) for each base in this set
- Returns:
average of the standard deviations of number of atoms added for each base
- get_routes(permitted_reactions: None | ReactionSet = None, debug: bool = True) RouteSet[source]
Get a RoutSet to products in this set.
- Parameters:
permitted_reactions – optionally restrict reactions to those in this
ReactionSet
- get_unquoted(*, supplier: str = 'any') CompoundSet[source]
Get all member compounds that do not have a quote from given supplier
- Parameters:
supplier – supplier name (Default value = ‘any’)
- grid() None[source]
Draw a grid of all contained molecules.
Attention
This method is only intended for use within a Jupyter Notebook.
- property id_num_poses_dict: dict[int, int]
Get a dictionary mapping compound ids to the number of poses
- property ids: list[int]
Returns the ids of compounds in this set
- property inchikeys: list[str]
Returns the inchikeys of compounds in this set
- property indices: list[int]
Returns the ids of compounds in this set
- interactive(function: Callable | None = None) None[source]
Creates a ipywidget to interactively navigate this PoseSet.
- property mols: list[Chem.Mol]
Returns the molecules of child compounds
- property name: str | None
Returns the name of set
- property names: list[str]
Returns the aliases of compounds in this set
- property num_atoms_added: list[int]
Calculate the number of atoms added w.r.t the base
- Returns:
list of number of atoms added values
- property num_bases_elaborated: int
Count the number of base compounds that have at least one elaboration in this set
- Returns:
number of base compounds
- property num_heavy_atoms: int
Get the total number of heavy atoms
- property num_poses: int
Count the poses associated to this set of compounds
- property num_rings
Get the total number of molecular rings
- property risk_diversity: float
Calculate the average spread of risk (#atoms added) for each base in this set
- Returns:
average of the standard deviations of number of atoms added for each base
- shuffled() CompoundSet[source]
Returns a randomised copy of this set
- property smiles: list[str]
Returns the smiles of child compounds
- property table: str
Get the name of the database table
- property tags: set[str]
Returns the set of unique tags present in this compound set
- write_CAR_csv(file: str | Path, amount: float = 1, return_df: bool = False, quoted_only: bool = False, get_ingredient_quotes: bool = True, **kwargs) DataFrame | None[source]
List of reactions for CAR
Columns:
target-name
no-steps
concentration = None
amount-required
batch-tag
per reaction
reactant-1-1
reactant-2-1
reaction-product-smiles-1
reaction-name-1
reaction-recipe-1
reaction-groupby-column-1
- Parameters:
file – output file
amount – amount of each product in mg
quoted_only – only choose reactants that have quotes
supplier – only choose reactants that have quotes from this supplier
kwargs – passed to
Recipe.from_reaction()return_df – return a DataFrame (Default value = False)
- write_postera_csv(file, *, supplier: str = 'Enamine', prefix: str = 'fragment') None[source]
Write a CSV formatted for upload to Postera’s Manifold
- Parameters:
file – path of the CSV file
supplier – supplier to use for quotes, (Default value = ‘Enamine’)
prefix – prefix to metadata columns, (Default value = ‘fragment’)
IngredientSet: Set of Ingredients
- class hippo.cset.IngredientSet(db: Database, ingredients: None | list[Ingredient] = None, supplier: str | list | None = None, debug: bool = False)[source]
An
Ingredientis aCompoundwith a fixed quanitity and an attached quote, theIngredientSetis a object representing multiple ingredients.Attention
IngredientSetobjects should not be created directly. Instead they are returned by several methods when working with Quoting and Random Recipe Generation.Selecting ingredients in the set
The
IngredientSetcan be indexed like a Python list:ingredient = ingredient_set[0] # first ingredient
To get the ingredient for a specific
CompoundID:ingredient = ingredient_set(compound_id=13)
- self + other[source]
Add another
IngredientSetthis set
- self(*, compound_id: int | None = None, tag: str | None = None) IngredientSet | Ingredient | CompoundSet[source]
Get members based on a compound_id or tag
- other: Compound | Ingredient | int in self[source]
Check if compound or ingredient is a member of this set
- getattr(self, key: str)[source]
For missing attributes try getting from associated
CompoundSet
- self[key: int] Ingredient[source]
Get a member by it’s index
- add(ingredient: Ingredient | None = None, *, compound_id: int | None = None, amount: float | None = None, quote_id: int | None = None, supplier: str | list[str] | None = None, max_lead_time: float | None = None, quoted_amount: float | None = None, debug: bool = False) None[source]
Add an
Ingredientto this set- Parameters:
ingredient –
Ingredientto be added, ifNonemust specify other parameters, (Default value = None)compound_id –
CompoundID (Default value = None)amount – amount in
mg(Default value = None)quote_id –
QuoteID (Default value = None)supplier – supplier name string or list (Default value = None)
max_lead_time – maximum lead-time for quoting (in days) (Default value = None)
quoted_amount – amount of associated
Quote(Default value = None)debug – increase verbosity for debugging (Default value = False)
- property compound_ids: list[int]
Compound IDs for all ingredients
- property compounds: CompoundSet
CompoundSetof all compounds in this set
- copy() IngredientSet[source]
Return a copy of this
IngredientSet
- property df: DataFrame
Access the raw DataFrame
- draw() None[source]
Wrapper for
CompoundSet.draw()
- classmethod from_compounds(*, compounds: CompoundSet | None = None, ids: list[int] | None = None, db: Database | None = None, amount: float | list[float] = 1, supplier: str | list | None = None) IngredientSet[source]
Create an
IngredientSetfrom aCompoundSetor IDs- Parameters:
compounds –
CompoundSetto use, ifNonemust provideidsanddb(Default value = None)ids – Compound IDs (Default value = None)
db – HIPPO Database (Default value = None)
amount – Amount(s) in
mg(Default value = 1)supplier – supplier to use for all quoting, (Default value =
None)
- classmethod from_ingredient_df(db: Database, df: DataFrame, supplier: str | list | None = None) IngredientSet[source]
Create an
IngredientSetfrom a DataFrame- Parameters:
db – HIPPO Database
df – DataFrame of Ingredients
supplier – supplier to use for all quoting, (Default value = None)
- classmethod from_ingredient_dicts(db: Database, dicts: list[dict], supplier: str | list | None = None) IngredientSet[source]
Create an
IngredientSetfromIngredientdictionaries- Parameters:
db – HIPPO Database
dicts – List of individual ingredient dictionaries
supplier – supplier to use for all quoting, (Default value =
None)
- classmethod from_json(db: Database, path: None | str, supplier: str | list | None = None, data: None | dict = None) IngredientSet[source]
Create an
IngredientSetfrom JSON data or a JSON file- Parameters:
db – HIPPO Database
path – path to JSON data (can be
Noneifdataprovided)supplier – supplier to use for all quoting, (Default value =
None)data – optional JSON data to parse, (Default value =
None)
- get_dict(data_orient: str = 'list') dict[source]
Get serialisable dictionary
- Parameters:
data_orient – passed to
pandas.DataFrame.to_dict(Default value = ‘list’)
- get_price(supplier: str | list[str] = None, none: str = 'error', debug: bool = False) Price[source]
Calculate the price with a given supplier
- Parameters:
supplier – supplier to use for all quoting, (Default value =
None)
- property id_amount_pairs: list[tuple]
Get a list of compound ID and amount pairs
- property ids: list[int]
Compound IDs for all ingredients
- property inchikeys: list[str]
InChI-keys for all ingredients
- interactive(**kwargs) None[source]
Wrapper for
CompoundSet.interactive()
- pop() Ingredient[source]
Pop the last compound in this set
- property price_df: DataFrame
DataFrame including prices
- set_amounts(amount: float | list[float]) None[source]
Set the amount(s) for all ingredients in this set, and update quotes
- Parameters:
amount – amount in
mg
- property smiles: list[str]
SMILES for all ingredients
- property supplier: str | list[str]
Supplier(s)